

Growth has also been driven by a range of factors including growing FX markets fragmentation, the decreasing balance sheet of FX dealers, the demand from regulators to develop a more holistic approach to best execution, and sharp increase in passive tracking assets under management with the focus on execution costs to minimise tracking errors.
In response to these factors, buyside trading desks are adopting algorithms to source liquidity from different banks, minimise trading costs and place trades in multiple venues, reducing information leakage and impact on the market. Algos support efficient market functioning, but users need to have sufficient knowledge and information to deploy them effectively.
Meanwhile, banks are investing in their algos, for example by incorporating artificial intelligence and machine learning, to enhance their executions and help clients reduce the cost of trading. With the increasing complexity and sophistication of algos has come a greater desire for transparency and advanced analytics tools.
Choosing the right algorithm for individual needs remains a challenge for the buyside. The main challenge is lack of common data and analytics – trading information is siloed and there has long been a lack of reliable benchmarks or rankings, despite the fact that a growing number of market participants are seeking independent, third-party evaluation of algos. Closing this information gap is critical to ensure greater transparency, efficiency and a level playing field.
Collaboration, algo provider “last mile” and data aggregation are crucial
Typically, the buyside is presented with myriad algos from a wide range of providers.
It is vital to choose an FX algo in a data-driven manner rather than relying on hope or luck. In this article I outline the many pitfalls which must be considered in any data-driven approach.
First, what is needed is a service that provides all the data. The devil is in the detail because the impact of seemingly small details on algo performance can be significant. (See case study and Figure 2).
Second, the feedback loop between algo provider (bank) and algo user is important. Algo providers (not TCA companies) are typically the ones with the most knowledge about their algos and hence are the best positioned to communicate with their clients. But without a common analytical framework and agreed up metrics algo providers and algo users cannot have a productive dialogue.
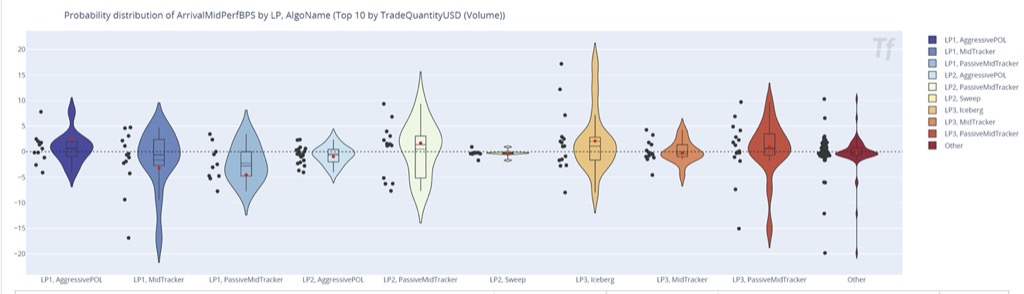
A typical algo user takes more risk in exchange for (hopefully) better return (see Figure 1) and guidance from the algo provider is crucial for solving this trade off in optimal way.
Finally, as buyers and users of FX algos, market participants can benefit significantly from other people’s knowledge (pooled data, decreasing the noise component on Figure 1) provided it is quantifiable, impartial, and reliable.
Choosing the right tool for the job
The first challenge for the buyside is that FX algo data is different across different banks – for example, their terminology and ways of presenting data are different. Algos also work differently and have different controls. To be helpful, the data on algos needs to be comparable.
Secondly, even with all the data, comparing algo performance is a technology challenge. While banks have the technology to do this, they focus on their own specific set of algorithms, and have no ability or data to provide an objective view of their strengths and weaknesses in comparison to those of competitors. It therefore is necessary for algo users (on the buyside) to invest in technology to store algo execution details and compare them in a consistent way. That is difficult for each buyside firm to do on its own, because of limited budgets to spend on this specific technology. It is also sub-optimal because it will create additional complexity – what is needed is one standard approach to promote effective dialogue. This makes the case for the third party with the capability to store execution detail and analyse FX algos for multiple clients. Using such a third party enables the buyside to benefit from economies of scale while keeping the flexibility of being able to carry out custom research (as every buy side has unique use case)
The third challenge facing the buyside in selecting FX algos is the independence of the data that they use as the basis of their decision.
Many algo evaluation firms are owned by major market participants, giving them an incentive to recommend a particular set of algos. It is not enough for an evaluation firm to be independent: the buyside needs to understand the detail of execution. As asset managers have fiduciary responsibility to their clients, they should not take a third party’s word on the relative merits of different algos. Instead, they should have the tools and access to the raw data to validate these merits themselves.
There should also be a feedback loop between the algo user and the algo provider, as sometimes people do not use algos correctly.
Why do people misuse algos? There may be a misunderstanding of what algos are doing. Sometimes people intervene too much by changing the parameters, restrict the algorithm to trade on certain venues or require unrealistically fast execution. No third party is qualified enough to advice client on all aspects of execution. That is the old model of transaction cost analysis provider, and it is sub-optimal. Direct dialogues between buyside and data vendors are the most efficient way to understand problems and come up with solutions.
An algo is a complex black box with lots of controls. The user can trade faster or slower, change the way he executes, switch to a more passive mode or stop the execution altogether. All such decisions contribute to performance. Ultimately, the user needs a technology that will record the P&L implications of all their decisions.
Collaboration is crucial. User permissioned data pooling and sharing is important so that algo users can work with their peers and liquidity providers to make better use of data assets. An independent provider can handle the data management while enabling market participants to remain in control of how they collaborate with each other.
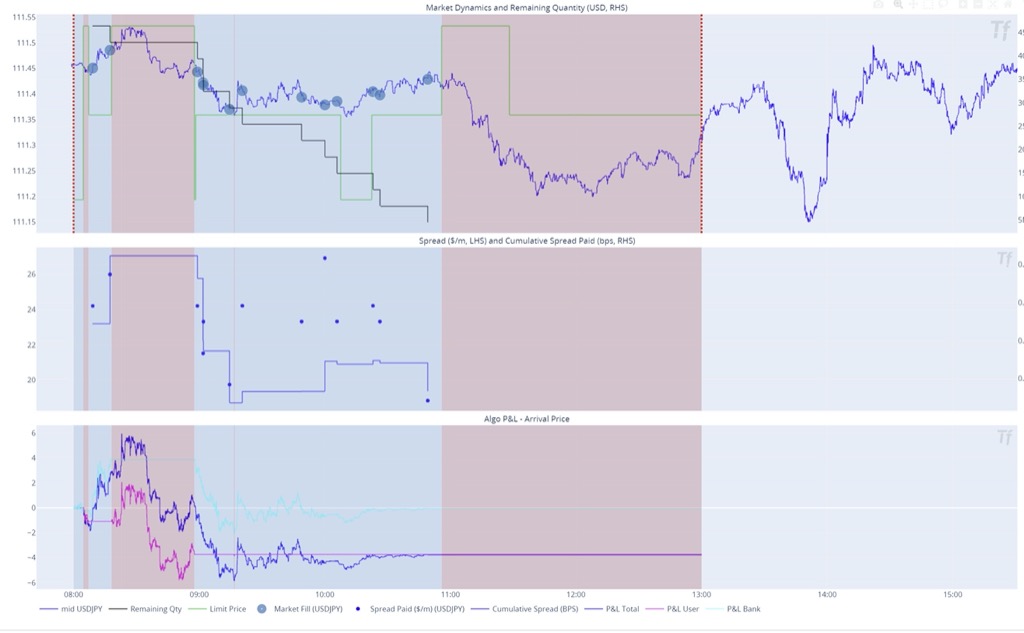
Case Study: Cleaning data for algo wheel
Consider a case in which a user aggressively manages the algo execution with a limit price (green line in the picture below). The algo is selling USDJPY, so every time the spot (blue line) is below the limit price the algo is not able to execute due to user instructions.
The P&L of such an “cyborg” algo execution is a joint effort of user and machine. A good technology solution should be able to split the attribution of the P&L between user and algo (machine). If this algo P&L is part of the algo decision framework (algo-wheel), its performance should be adjusted for user performance. In most scenarios, only machine P&L should be used. The implementation details are crucial as well and the technology solution should be transparent and customizable to the end user building an algo wheel. Otherwise, it can be a “garbage-in” / ”garbage-out” type of scenario.
Solutions: standardised data and engagement
Let’s now turn to the solutions to these challenges. The first critical piece of the jigsaw is to have all the data in a standard format and located in one place. That involves an expensive technology layer that someone has to build. The buyside needs to be able to control this data so that it can fulfil its fiduciary responsibility by cross-checking the results. That means having a standard data and analytics layer that allows asset managers to rank algos and create allocation rules.
The second element, as mentioned above, is having a dialogue with the bank (or other algo provider) about commonly accepted metrics.The third element is the ability to learn and expand your horizons. There are more products in the market than an individual buyside firm will have access to. Theoretically, a person can trade 50 algos, but typically people trade only five to 10 because they know those and not others.
Using your 10 favourites and not looking around at alternatives is sub-optimal. Data pooling is the answer. Each user should use 5 or 10 algos according to their needs but they should be selected on a fully data-driven basis from the universe of 50 possible ones.
Having a database that aggregates performance improves efficiency. It is useful to have access to all sorts of user feedback in a quantified way and to be able to conclude that certain algos seem to be best for certain scenarios. The buyside aims to have a framework to learn about algo performance in a relevant trading context. That trading context couldrange from a basic variable such as time of the day to a range of market conditions such as market trend, volatility and liquidity conditions.
Inertia can be a problem
There is significant inertia around which algos the buyside uses. The execution desk decides which algo to use and whether to use an algo at all. If they decided to deviate from their usual algos and it went badly, they would be questioned about why they made that decision.
Although data is available from banks, the lack of common, independently calculated metrics make it difficult to compare algo across providers. Having a common platform allows an algo provider to produce a “data pack” for potential users. This data pack would provide the potential algo user with statistical data for many algo runs and allow them to justify using the new set of algos, if indeed the presented data suggests that it make sense. The data pack helps to overcome inertia and help to arrive to more optimal selection of algos.
An execution desk is rarely challenged on their choice of algos as it is commonly accepted that experimentation is expensive. Typically, people focus on outlier runs. If the execution desk tried a new algo without any statistical evidence on the performance and the result is disappointing, they would be challenged on why the experimentation was done, this is why the execution desk is conservative. It does not want to explore something new without a good reason. However, there is no doubt that trying new algos improves efficiency of execution over time. It just must be done in efficient, data-driven way. If a common, trusted statistic demonstrates that an algo works in certain scenarios and has been verified to be better than the status quo, then the risk of experimentation is reduced.

Conclusion: a dialogue based on common data and metrics
Clearly, every asset manager is different because they are complex organisations. They have to decide their own approach, but they generally lack the resources to invest heavily in technology, data collection and standardisation. Even if the buyside embarks upon setting up the technology independently, the dialogue with banks would be challenging because each asset manager would speak to each bank in a different language.
Asset managers can benefit significantly from an independent tool that gives them access to all the data they need to evaluate FX algos across different providers. To achieve better execution, both liquidity providers and liquidity consumers need to engage better, and what has been missing in that interaction is a common data platform that allows the buyside to extract the information that they need in a data-driven way. The sell side will benefit from more efficient marketplace for liquidity in general and algos in particular. They can connect to their client directly if data and analytics metrics are common, transparent and controlled by no-one and hence remove intermediaries from their dialogue. Liquidity optimisation requires a dialogue based on common data and metrics, while keeping things flexible so a complex institution can validate that the algos they select will help them achieve their goals.
Finally, the independent third party should not be the sole judge of metrics and the quality of execution. Instead, it should only serve as a flexible technology and analytics layer allowing market participants to use it and draw their own conclusions. This is likely to improve market efficiency and address the challenges outlined above.